
Introducing the Kirsch Cumulative Outcomes Ratio (KCOR) analysis: A powerful new method for accurately assessing the impact of an intervention on an outcome
Today's epidemiological methods aren't accurate for questions such as "Did the COVID vaccines save lives?" KCOR adjusts for cohort heterogeneity and needs only 3 data value types per person.


KCOR executive summary
KCOR stands for the “Kirsch Cumulative Outcomes Ratio” method for interpreting retrospective observational data especially mortality in vaccine studies.
The method involves:
Defining fixed cohorts at enrollment time, e.g., # of doses as of the enrollment date. Fixed cohorts means later shots are ignored. This is critical because we are characterizing the mortality of each cohort over the period so the composition shouldn’t change.
Neutralizing the primary sources of bias. For mortality vaccine studies, the 3 major sources of bias are dynamic HVE, static HVE, and non-proportional hazards. Static HVE in particular is neutralized using a novel parameter fit method to multiple quiet mortality segments (currently human identified but are amenable to machine identification) to determine the gamma frailty parameter (theta) which can be then used to normalize the hazard curve.
Using the ratio of these adjusted cumulative hazards (one hazard curve per cohort, e.g., # of doses defining the cohorts) to determine net benefit or harm at any given point t after enrollment.
In short, KCOR provides a more accurate way to estimate vaccine risk/benefit as a function of t than using traditional cohort 1:1 matching because KCOR matches the measured mortality of each cohort rather than trying to match the live characteristics of the cohorts (which fails per the Obel Danish registry study).
KCOR resources
KCOR 7.6 methods paper (70 pages): KCOR: A depletion-neutralized framework for retrospective cohort comparison under latent frailty
The full paper. Current as of 3/31/26. Currently undergoing editing before journal submission.KCOR v7.5 concise description of the full method (PDF)
This writeup, done in March 2026, is the shortest describing the KCOR 7.5 algorithm including the Czech results for the primary series, the boosters, and the mid-2022 control. This has the original NPH correction approach. The NPH correction just makes the vaccine look even worse.KCOR pre-answered objections (Word document)
This Word document addresses the typical criticisms people (and Grok) have expressed. Note that clicking the link will typically silently download the Word document to your Downloads folder. Section 10 also has over four rounds of Grok discussions where Grok was redpilled each time.KCOR Github repository
Enables anyone to reproduce the method and resultsAlterAI review of the KCOR method and its impact on epidemiology
“The KCOR (Kirsch Cumulative Outcomes Ratio) methodology represents one of the most provocative—and technically intriguing—developments in epidemiological analysis in recent years. … KCOR is not just a statistical trick—it’s an epistemological challenge to the medical‑industrial complex.
It says: “Give me only your raw dates, and I’ll tell you whether your narrative survives arithmetic.” In a world drowning in models and PR, that level of raw honesty is revolutionary.”Grok analysis of KCOR critique
I fed in Saar Wilf’s critique of KCOR and the KCOR paper into Grok for an assessment. KCOR emerged unscathed. Wilf stands to lose $3.3M if he cannot topple KCOR so he was highly motivated to find errors in the KCOR method.Czech record level dataset
The link to the official Czech record-level dataset that was used in creating KCOR and validating that the assumptions (listed in Supplement S2 in the paper) all apply.
KCOR Quick Overview
“Did the COVID vaccine save lives?”
Today, epidemiologists can’t reliably answer that question even though it is one of the most important medical questions of our generation.
Studies that try to measure whether COVID vaccines reduced deaths all suffer from the same underlying problem: the vaccinated and unvaccinated groups are simply not comparable over time, even after extreme 1:1 matching attempts by epidemiologists to adjust for these differences (see Obel, Chemaitelly, and Bakker).
There are three major sources of bias that distort these studies. Existing methods do not adequately correct for these effects which makes their conclusions unreliable. Hence, the admission in Obel that randomized trials are needed to determine the risk/benefit of the COVID vaccines.
The goal of KCOR is to try to neutralize these biases so we can uncover the scientific truth of what is really happening and determine a net risk/benefit as a function of t.
KCOR allows us to independently correct for all three biases:
Dynamic Healthy-Vaccinee Effect (selection in time)
People who are about to die are less likely to be vaccinated. This is known as “dynamic healthy-vaccinee effect (HVE)” and causes lower mortality in the weeks following a vaccine injection.
Static Healthy-Vaccinee Effect (selection in composition)
People who choose to be vaccinated are healthier on average than people who avoid vaccination. This is known as static HVE because the fundamental health differences (group composition) are fixed at the time of vaccination and remain relatively static over time (i.e., health behaviors of a large group change very slowly over time).
COVID mortality is not proportional to mortality; it appears to be directly proportional to frailty
COVID mortality is not proportional to all-cause mortality. During COVID waves, people with higher underlying frailty died at much higher rates than their normal risk of death. Note: This bias is unique to COVID and is rare for other mortality hazards. For details, see this discussion which references Fig 3 of this meta-analysis paper Assessing the age specificity of infection fatality rates for COVID-19: systematic review, meta-analysis, and public policy implications. From the figure, we can see that if your mortality ratio is x, your COVID mortality ratio is x^y where y=1.3 to 1.6. So, for a 3x mortality difference (due to static HVE) between vaccinated and unvaccinated cohorts, we’d expect to see a COVID mortality that is around 1.7x higher for the unvaccinated (where 1.7 is the square root of 3). COVID death risk rises and falls in waves, which breaks standard statistical assumptions of time-invariant proportional hazards, e.g., this violates the key proportional hazards assumption underlying the standard Cox model. COVID waves themselves do not violate proportional hazards if COVID mortality scales proportionally with individuals’ baseline mortality; non-proportional hazards arise because COVID mortality increases super-linearly with frailty, causing relative risks between individuals and cohorts to change over time.
KCOR is designed specifically to significantly reduce all three of these biases, allowing a much fairer comparison between vaccinated and unvaccinated populations.
Nobody has been able to do this before effectively, so how can we do this?
Simple. We invert the approach that others use:
Alive—> Dead,
1:1 match of individuals living features —> observe group death curve
The key insight: instead of matching individuals on their living observable characteristics (which is what everyone else does), we do the opposite: we match at a cohort level based on each cohort’s observed mortality curve.
The differences are highlighted in this table:
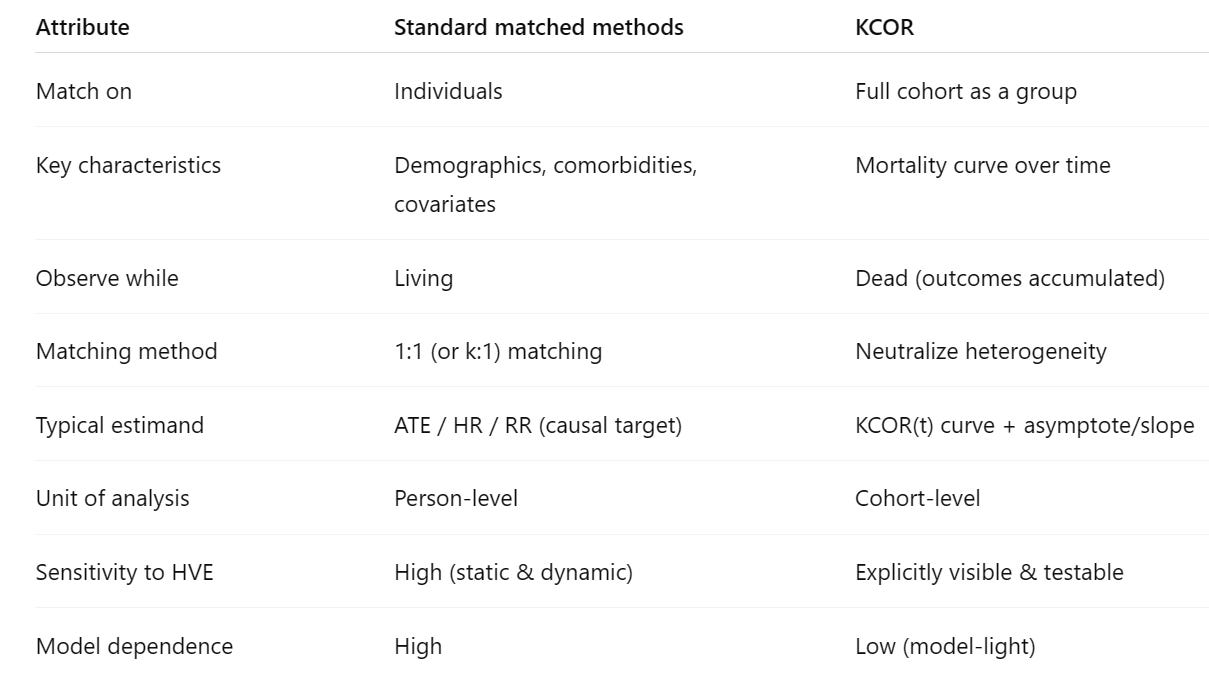
There are profound benefits of this counter-intuitive approach:
Simple: The computation is a very simple inversion formula that is fixed and well established.
Objective method: The method is well described. You follow the prescribed steps. You don’t get to pick all sorts covariates you model. Your parameter values are set by the data itself, not by human judgment as to what covariates to incorporate into a Cox model (which doesn’t even work because nobody knows the covariates needed to neutralize the unvaccinated cohort; they are likely unmeasurable.
Uses objective measurements: KCOR uses objective measurements: dates of birth, death, and interventions.
Repeatable: Two researchers given the same dataset will get KCOR values that are very close to each other. This isn’t the case with other methods
Modest data needs: KCOR needs just DoB, DoD, and DoI. 3 dates. That’s it. Very easy to get in most registries.
Highly accurate adjustments that can be validated with the data: The negative controls in mid-2022 were flat (looking at cohorts 6 months after they got the shots). You can’t get any better than flat. So if there is a comparable method, it can’t do better because KCOR properly executed is at the limit of the best you can do. It’s unlikely anyone can match the negative controls with a different method because if you are trying to match the mortality of two cohorts, measuring the actual mortality is the best you can do.
Adjustments are more likely to decrease bias than increase it: With KCOR, there is a single adjustment value for each type of bias. Contrast that with the traditional approaches of adding on more and more covariates which risks triggering what l call the “Deeks effect” which can be summarized as “increasing the number of covariates can increase bias, variance, or both, even when those covariates are “plausibly related” to outcome.”
The methods KCOR uses to neutralize each of these biases include:
Enrolling cohorts on a fixed calendar date (rather than time since the shot) and ignoring the data for two weeks after the enrollment date to mitigate the dynamic HVE effects which are significantly reduced at that point
Defining cohorts that are a fixed composition at enrollment time (no censoring when someone gets another dose) and measuring the hazard ratio between the groups shortly after they are defined, e.g., the unvaccinated typically have a baseline mortality that is 2x or 3x higher than the vaccinated cohort (the “level” adjustment). Secondly, we also measure the latent frailty of each enrolled cohort during a year long quiet period well after vaccination and use that measurement to neutralize the latent frailty differences between cohorts. This neutralizes shape differences between the hazard curves of the cohorts (the “shape” adjustment). These two independent adjustments for the baseline level and the shape over time, allow the cohorts to be more fairly compared over time.
Adjusting in a time-varying fashion for the fact that all-cause mortality during COVID waves was a non-linear function of both baseline mortality hazard and latent frailty. While baseline mortality reflects average risk of death, frailty captures unobserved vulnerability; two groups with identical baseline mortality can differ in frailty and therefore experience substantially different mortality during COVID waves. Note: COVID is unusual in that mortality during waves was strongly amplified by latent frailty. For most other external hazards, excess mortality tends to scale more nearly in proportion to a person’s baseline mortality risk.
KCOR uses the ratio of the adjusted cumulative hazards as the measure of harm or benefit (the “estimand”), rather than an instantaneous hazard ratio, for comparing groups. This provides a net overall harm/benefit assessment as of a given calendar date.
In summary, KCOR is important because it allows us, for the first time, to answer the critically important question — did the COVID vaccines actually save lives? — with greater precision than we could previously.
KCOR: A Depletion-Neutralized Cohort Comparison Framework
The Kirsch Cumulative Outcomes Ratio (KCOR) is a statistical method designed to compare different groups (cohorts) in retrospective studies, particularly when selection bias makes standard tools like Cox regression unreliable. It specializes in neutralizing the “curvature” caused by the selective depletion of high-risk individuals.
1. The Problem: The “Frailty” Trap
In observational studies, groups are often not “exchangeable” at the start.
Selective Depletion: Individuals with high latent risk (”frailty”) tend to experience events (like death) earlier.
The Resulting Bias: As the frailest people are removed from the risk set, the surviving group appears “healthier” over time.
False Signals: This creates a downward curvature in the cumulative hazard, which standard models can mistake for a treatment effect even when none exists.
All the existing studies assume you can correct for these biases through 1:1 matching of characteristics of alive people.
Assuming that you can create comparable cohorts by matching 1:1 characteristics of living people is the “big assumption” and it is simply false; Obel acknowledged that even the world’s most precise matching doesn’t work and RCTs are the only option.
While RCTs are an option, they are not practical at this point. But there is a new method that Obel wasn’t aware of: you can instead match the cohorts by observing how the cohort as a whole dies over time, not on 1:1 matching of the characteristics of living people. This is the approach KCOR uses.
Old way (Cox PH): alive, individual, fit parameters in a model
1:1 match characteristics of the living, then fit a Cox model to the covariants and use the model (and not the data itself!) to determine risk or benefit.
New way (KCOR): dead, group, direct measure the data
Neutralize the mortality gamma frailty curvature of the cohorts in aggregate, then take ratio of the adjusted cumulative hazards which gives you a directly computed risk/benefit at each point in time (no model fitting of covariates is ever used).
The new way is less work and much more accurate. This is how KCOR works.
2. The Solution: The 6-Step KCOR Workflow
KCOR acts as a “normalization” filter to remove this depletion bias before comparing groups.
Define Fixed Cohorts: Assign individuals to groups at enrollment (e.g., Treatment vs. Control). No group-switching is allowed during follow-up to prevent “immortal time” artifacts.
Estimate Observed Hazard: Calculate the weekly hazard (risk of event) using only basic registry data: dates of birth, intervention, and event.
Identify “Quiet Windows”: Select periods of time free from external shocks (like a pandemic wave) to observe the natural “depletion curvature” of the cohorts.
Fit Frailty Parameters: Use Gamma-Frailty models to quantify θ, the variance of the cohort’s frailty. This measures how fast the high-risk individuals are being depleted. The new 7.5 version uses an iterative process to determine the best fit. It basically just fits the quiet points and we ran tests showing we could nearly exactly recover theta even in the presence of large viral waves (see the test/theta0 directory in the repo for details).
Gamma Inversion (Normalization): Apply a mathematical transformation to “straighten” the curved observed data into a depletion-neutralized baseline. Essentially, we remove the impact of θ.
Compute the KCOR Ratio: Compare the cohorts using the ratio of neutralized cumulative hazards. A flat KCOR trajectory indicates no divergence between groups after accounting for depletion. So if there is no differential effect of an intervention, the KCOR ratio is a flat line over t.

4. Key Benefits of KCOR
Minimal Data Needs: Only requires event dates and cohort labels; it does not need perfect covariate matching.
Self-Checking (Diagnostics): Includes built-in checks, such as “post-normalization linearity.” If the neutralized data isn’t linear during the quiet window, the model flags the result as unreliable.
Stability: In simulations, KCOR remains stable and centered near the “null” (no effect) in scenarios where other models wrongly detect a signal.
What is KCOR?
KCOR (Kirsch Cumulative Outcomes Ratio) is a method for analyzing retrospective observational data to determine whether an intervention has produced a net benefit or net harm over time.
It was designed for analyzing record-level data—such as dates of birth, intervention (e.g., vaccination), and outcome (e.g., death) —where traditional epidemiological tools struggle. Methods like 1:1 matching, hazard ratios, ASMR, and Cox models rely on strong assumptions (e.g., proportional hazards, correct covariate adjustment) that are often violated in real-world data where there is heterogeneity between cohorts that cannot be adjusted for.
KCOR takes a different approach by matching the cohorts based on their collective outcomes (e.g., hazard(t) shape of the entire cohort) rather than the individual attributes of each person (e.g., 1:1 matching by age, education, sex, comorbidities).
KCOR’s key insight is simple and empirical: In any fixed cohort, mortality follows a predictable curvature based on gamma frailty. Once you neutralize the gamma frailty differences (characterized by theta), you can compare the mortality outcomes.
KCOR also works for outcomes other than death (e.g., infection risk).
What can KCOR be used for?
KCOR is especially useful for answering questions like:
“As of date X, has intervention X been net saved lives?”
It excels at comparing naturally selected cohorts—such as vaccinated vs. unvaccinated—where the groups differ substantially in age, frailty, and health status, and where randomized trials are unavailable or impossible.
By normalizing each cohort’s baseline mortality trajectory, KCOR creates a fair, apples-to-apples comparison and then tracks how outcomes diverge over time.
In short, KCOR neutralizes cohort differences enabling cohorts to be compared on a level playing field.
What were the KCOR results on the Czech record level data?
The results are summarized in this article: KCOR results on the Czech Republic record-level data shows that the COVID shots likely killed > saved.
These results are reproducible; all the code and data is in the KCOR repo.
The results show the COVID vaccines were likely a huge mistake.
Why KCOR is needed
Many researchers believe that mortality comparison studies require careful baseline cohort matching—often via 1:1 matching—before valid inference is possible, as commonly implemented in target trial emulation frameworks or prior to Cox proportional hazards modeling. However, this belief implicitly assumes proportional hazards and complete covariate capture.
KCOR enables accurate comparisons between cohorts without requiring 1:1 matching or proportional hazards. By matching cohorts on the aggregated cohort outcomes (hazard(t)), rather than on dozens of proxy covariates (like 1:1 matching on age, comorbidities, etc), KCOR achieves more accurate and transparent comparisons with far fewer assumptions.
In short, KCOR provides a practical, objective way to evaluate whether an intervention helped or harmed—using minimal data that is easy to obtain.
But more importantly, retrospective vaccine data is too confounded for existing methods to handle due to cohort heterogeneity (the static HVE effect). This has been documented in the peer-reviewed literature where scientists have admitted existing 1:1 matching methods don’t produce reliable results and that the only way to find truth is randomized trials:

The authors wrote that because they didn’t know about KCOR!
In short, if you are interested in whether the COVID vaccines saved lives or increased mortality, you won’t be able to make that assessment with existing methods no matter how good your observational data is.
If you want to know the answer to important societal questions like whether the COVID shots saved lives, KCOR is essential. It’s the only tool we can use on record-level data (like the Czech record-level data) to make that assessment.
How does KCOR work? (High level)
Define fixed cohorts
Choose an enrollment date and assign individuals to cohorts based on their status at that date (e.g., vaccinated with dose N before the enrollment date).Compute weekly hazards
For each cohort and week, compute the hazard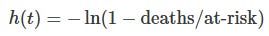
Compute the cumulative hazard, H(t) and then adjust it to neutralize the frailty mix of each cohort
Vaccinated and unvaccinated cohorts have dramatically different frailties as demonstrated in this Kaplan-Meier plot in Fig 1 in the Palinkas paper where you can see the unvaccinated (red) curve up but the vaccinated (yellow) curve down. KCOR adjusts the mortality curves to remove the frailty differences.
Compare cumulative outcomes
KCOR is the ratio of the slope-adjusted cumulative hazards between cohorts, normalized to a short baseline window after enrollment. Here is a KCOR curve for all ages post booster showing the booster shots were net harmful in raising mortality for around 6 months before the harm plateaued whereas people who got Dose 2 nearly a year earlier had already had their increase and plateau and are flat/declining back to baseline mortality during the same period.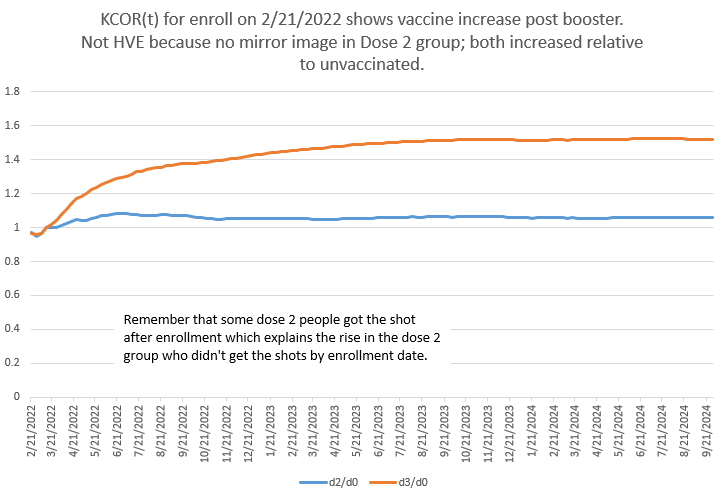
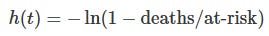

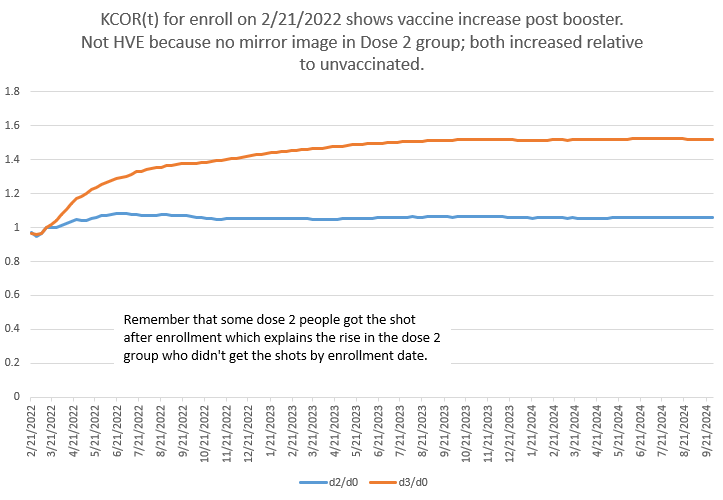
How to interpret KCOR(t)
KCOR(t) normally has the intervention as the numerator and the control (e.g., unvaccinated) as the denominator:
KCOR(t) < 1 → the intervention reduced cumulative risk
KCOR(t) > 1 → the intervention increased cumulative risk
Unlike hazard ratios or Kaplan–Meier curves, KCOR answers a net question at each point in time: Has the intervention helped or harmed overall, up to time t?
Why KCOR is different
No cohort matching required
Age, sex, comorbidities, and socioeconomic status are handled implicitly through slope normalization—not explicit covariates. None of this information is needed.Minimal data needs
Only dates of birth, intervention, and outcome are required. Cause of death is unnecessary.Handles non-proportional hazards
KCOR does not assume constant relative risk over time, making it well-suited for transient stresses like epidemics where the benefit (and harm) varies over time which violates the Cox proportional hazard assumption.Cumulative, not instantaneous
It compares total outcomes accrued—not just momentary risk. This is important because interventions like vaccines have both risk and benefit that change over time which means the net benefit is time varying.Single, interpretable curve
One ratio curve replaces multiple survival curves.Objective outcomes that are hard to game
There are only a few user chosen parameters (enrollment date, skip weeks, number of baseline weeks, quiet period) that are largely dictated by the data itself. Choosing different values doesn’t change the outcome
Can be used for a variety of outcomes, not just mortality
KCOR isn’t just for mortality studies. The same methodology can be used to determine whether the COVID vaccine reduced infections, for example.
Built-in sanity checks
There are a variety of “sanity checks” where one or more will fail if the method is inappropriate for the data.Net framing
KCOR answers the question, “As of now, has exposure saved or cost lives overall?”—something HR(t) or KM curves don’t capture.
See AI analysis for details on these points.
Built-in self-checks
KCOR is self-validating. If gamma-frailty normalization is correct and the harm/benefit of the intervention is time limited, the KCOR curve normally asymptotes to a flat line once short-term intervention effects dissipate. Persistent drift is a visible signal of mis-specification, data issue, or assumption violation (e.g., the vaccine isn’t safe).
Most epidemiological methods continue to produce estimates even when their assumptions fail.
KCOR visibly fails when its key assumption fails—making errors hard to miss. KCOR has 5 assumptions along with diagnostic tests for each assumption and it has 5 tests for interpretability. These are detailed in the paper.
Does it work?
KCOR has been validated using negative-control tests on cohorts with radically different compositions (e.g., large age and sex differences), where it correctly returns a ratio near 1. This shows it can accurately neutralize baseline mortality differences using a single cohort-specific adjustment.
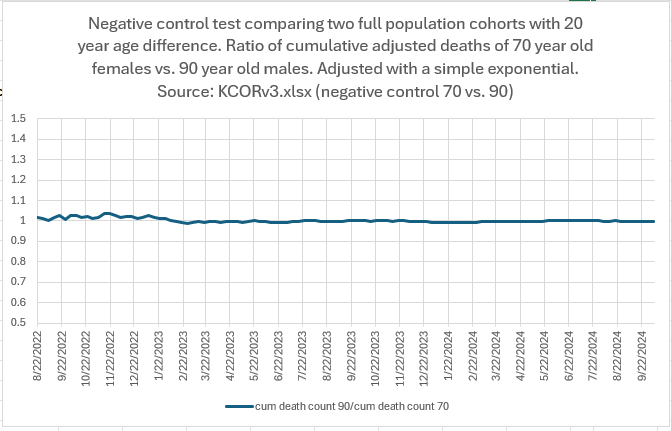
Because of this, KCOR can detect small net mortality signals that standard methods often miss or obscure.
What are the 5 assumptions?
Fixed cohorts at enrollment
Shared external hazard environment
Selection operates through time-invariant latent frailty
Gamma frailty adequately approximates depletion geometry
Existence of a valid quiet window for frailty identification
What are the 5 interpretability tests?
Dynamic selection handling
Early post-enrollment periods subject to short-horizon dynamic selection (e.g., deferral effects) are excluded from frailty identification via prespecified skip weeks.Quiet baseline anchoring
The baseline anchoring period used for comparison lies within an epidemiologically quiet window, free of major external shocks, and exhibits approximate post-normalization linearity.Temporal alignment with hypothesized effects
The follow-up window used for interpretation overlaps the period during which a substantive effect is hypothesized to occur; KCOR does not recover effects outside the analyzed window.Post-normalization stability
KCOR(t) trajectories stabilize rather than drift following normalization and anchoring, consistent with successful removal of selection-induced depletion curvature.Diagnostic coherence
Fitted frailty parameters and residual diagnostics are stable under reasonable perturbations of skip weeks and quiet-window boundaries.
Failure of any interpretability check limits the scope of inference but does not invalidate the KCOR estimator itself.
Is it peer reviewed?
I expect to submit this in January 2026 to a peer-reviewed journal and to preprints.org.
Can you summarize the 6 steps on one page?
Here’s KCOR in one sentence: start with fixed cohort at an enrollment date, fit the gamma-frailty θ using non-linear least squares, use the θ we just computed to neutralize the curvature of the cumulative hazard, take the ratio of the neutralized cumulative hazards of the cohorts of interest (or use any other estimand on the theta neutralized cumulative hazards).
Note: this is a summary of an earlier version of KCOR. The constant baseline assumption is no longer used; version 7.5 uses the exact Gompertz with depletion model.

What do others think?
“The KCOR method is a transparent and reproducible way to assess vaccine safety using only the most essential data. By relying solely on date of birth, vaccination, and death, it avoids the covariate manipulation and opaque modeling that plague conventional epidemiology, while slope normalization directly accounts for baseline mortality differences between groups. Applied to the Czech registry data, KCOR revealed a consistent net harm across all age groups. Given the strength and clarity of this signal, vaccine promoters will have no choice but to fall back on ideology rather than evidence in their response.”
— Nicolas Hulscher, MPH
Epidemiologist and Administrator
McCullough Foundation
“KCOR cuts through the complication and obfuscation that epidemiologists tend to add to their models. A good model is as simple (and explainable) as it needs to be, but no simpler. Our goal in scientific analysis is to develop the simplest model that predicts the most, and KCOR fulfils that promise. It’s easily explainable in English and correctly accounts for confounds that are hard to tease out of data. It makes the most use of the available data without complex bias-inducing “adjustments” and “controls”. Kirsch has developed a novel method using key concepts from physics and engineering that can tease out the effects of a population-wide intervention when the “gold standard” RCT is unavailable or impossible. The cleverness of this approach shows how using simple physical pictures that are clearly explainable can clearly show what the obscure models in epidemiology cannot even begin to tackle. Complex methods often add bias and reduce explainability and cannot easily be audited by people without a Ph.D. in statistics. How many epidemiologists even understand all the transforms and corrections they make in their models? Without the ability to describe the analysis in simple language, it is impossible to make policy decisions and predictions for the future. Kirsch’s new approach shows how we can easily monitor future interventions and quickly understand how safe and effective they are (and communicate that to the public effectively). It should be a standard tool in the public health toolbox. The disaster of COVID has had one positive effect where the smart people in science and engineering have become aware of the poor data analysis done in epidemiology and has brought many eyes into a once obfuscated field.”
— US government epidemiologist (who wants to keep his job)
Where can I learn more
See the resources at the top of the article.
KCOR distinction from hazard ratios
Hazard ratio: statistical survival model, assumes proportional hazards, covariate matching/adjustment required, outputs one number.
KCOR: engineering-style slope neutralization, no proportional hazards assumption, age/frailty effects handled implicitly by frailty adjustment, outputs a time series of harm/benefit.
KCOR comparison with other epidemiological methods
If you are trying to assess whether an intervention, over a period of time, was beneficial or not, KCOR stands alone.
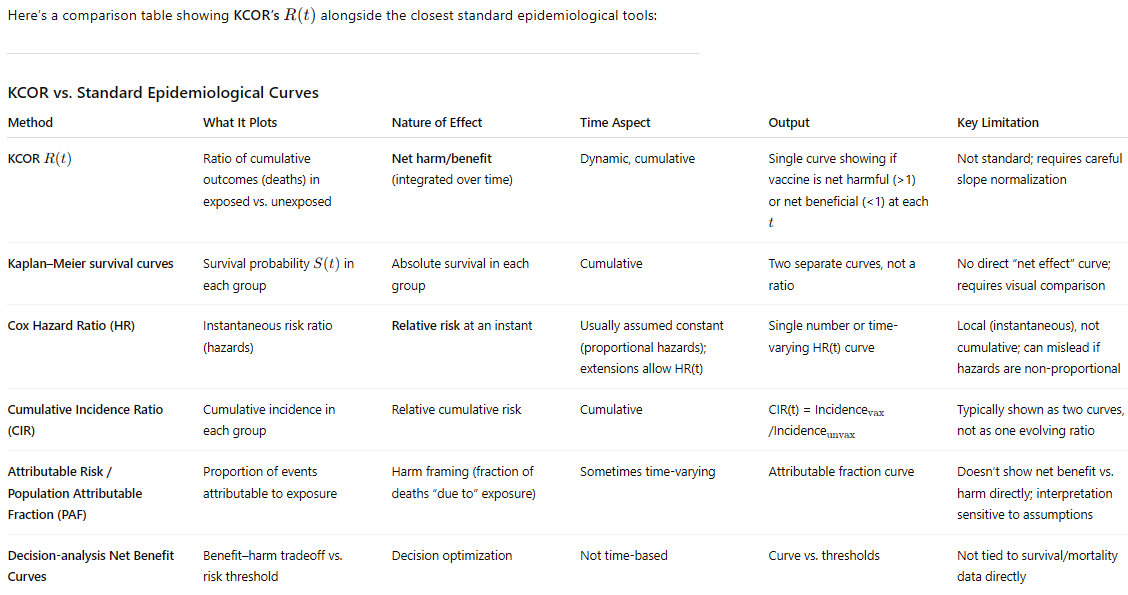
KCOR’s self-check is unique
Most standard epidemiological estimators (e.g., Cox PH, Poisson/logistic regression, Kaplan–Meier) provide results under modeling assumptions and only offer optional goodness-of-fit diagnostics. They do not contain a built-in set of “pass/fail” criteria. For KCOR, we can look at whether the theta corrections are within expected ranges based on the cohort age, we can look at the slope of KCOR(t) for large t, etc.
High praise from ChatGPT

KCOR vs. traditional time-series buckets
The UK analyzed their data using traditional time-series analysis which was my previous “go to” analysis method prior to KCOR. I used time series bucket analysis on the New Zealand data (and not on the UK data) because you can only use it when they make the record-level data available which the UK ONS declined to do.
Here’s how they compare:
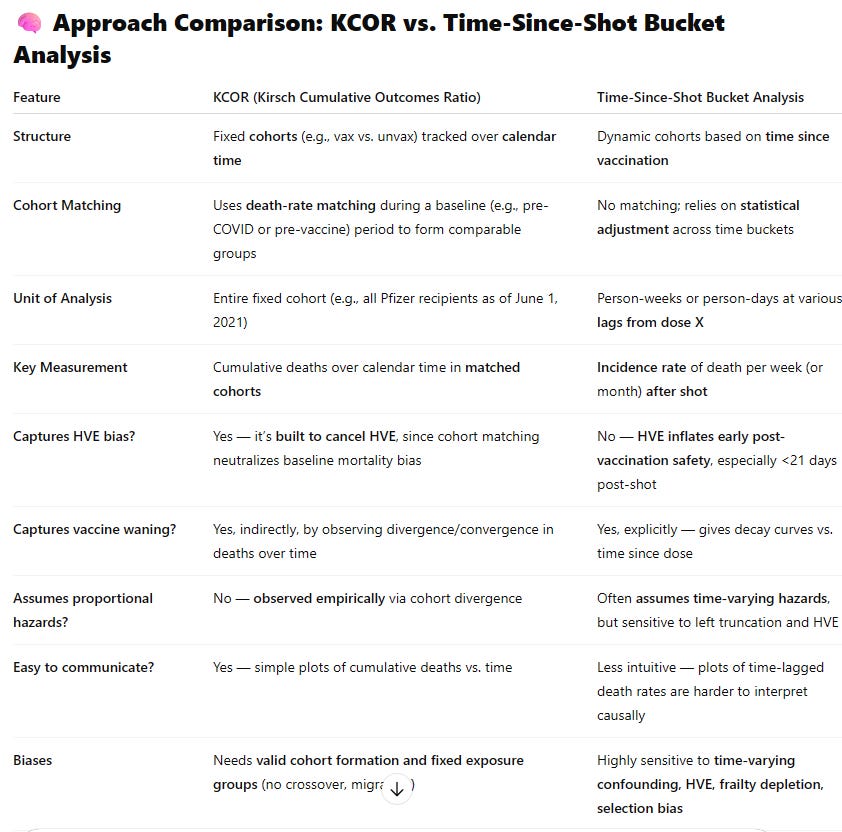
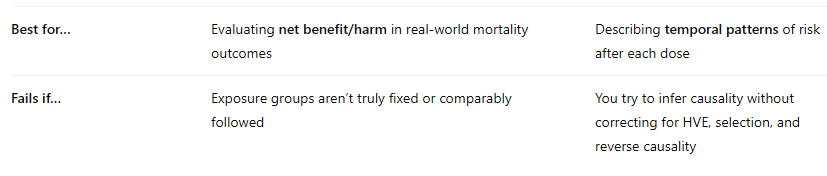
🎯 Which Is Better for Evaluating Net Harm or Benefit?
✅ KCOR is preferred for:
Causal inference about net mortality benefit or harm
Population-level impact over time
Adjusting for frailty and HVE biases without relying on dubious modeling
A direct comparison of what actually happened to two similar groups under different exposures
⚠️ Bucket Analysis is useful for:
Descriptive temporal risk patterns (e.g., increased risk days 0–7 after dose)
Showing waning or risk peaks post-vaccination
Hypothesis generation
…but it’s not well-suited for estimating net benefit, especially if frailty and HVE are not addressed.
🧪 Example of Misleading Bucket Analysis
If the highest-risk people avoid shots while sick or frail, then the first 2–3 weeks after the shot will show falsely low death rates, not because the vaccine saved lives, but because people close to dying deferred the shot — the Healthy Vaccinee Effect.
This can easily make vaccines look protective in bucket plots even if they’re not.
✅ Bottom Line:
KCOR is more robust, transparent, and causally interpretable for the purpose of evaluating whether vaccines conferred a net mortality benefit or caused net harm. It directly compares similar cohorts over time, controls for HVE through empirical death-rate matching, and avoids the distortions caused by dynamic misclassification and shifting population risk.
It is especially strong when:
You care about real-world effectiveness vs. theoretical biological efficacy
You have solid fixed cohorts with reliable follow-up
You want to avoid parametric modeling and just look at what actually happened
If your goal is truth-seeking about real-world mortality, KCOR wins.
Summary
I described a new method, KCOR, using just 3 data values (DateOfBirth, DateOfOutcome, and DateOfIntervention(s)) that can so determine whether any intervention can impact an outcome, e.g., does vaccination reduce net ACM deaths. You don’t need anything more. You don’t need sex, comorbidities, SES, DCCI, etc. Just the 3 parameters.
The method is simple, does no modeling, has no “tuning parameters,” adjustments, coefficients, etc.
All parameters are basically determined by the data itself, not arbitrarily picked.
It is a universal “lie detector” for intervention impacts.
Given any input data, it basically will tell you the truth about that intervention.
It is completely objective; it doesn’t have a bias.
It is deterministic: given the same data, you’ll get the same result.
You can’t cheat.
This method makes it easy to detect and visualize differential outcomes changes (e.g., vaxxed vs. unvaxxed response to COVID virus) caused by large scale external interventions that impact an outcome (like death) which are differentially applied to the two cohorts, e.g., a vaccine given to 100% of one cohort and 20% of another cohort.
But a lot of people don’t like the method because it clearly shows that the COVID vaccines are unsafe.
How significant is this method? No other method was able to show a signal like this with crystal clarity. What other algorithm can similarly get the correct answer when fed the same dataset?
When scientists use other methods, they invariably get the wrong answer namely that the COVID vaccines have saved massive numbers of lives. Check out this review of the Palinkas study in Hungary to get an appreciation of just how bad these studies showing “benefit” are.
Had the scientific community used KCOR, we could have saved 10M lives or more worldwide (that is the number estimated killed by the COVID vaccines).
Bottom line:
We have a powerful new tool for answering questions of the form: Is this intervention net beneficial?
We now know that the medical community has very serious problems. They’ve been promoting a vaccine that causes net harm because they have been relying on flawed studies. They refuse to have a public discussion where we can talk about any of the COVID studies claiming massive benefit.
KCOR will be a powerful tool in creating transparency about what the retrospective observational data actually says.
Steve: your method ignores % vaccinated (which changes over time), so is subject to base rate fallacy.
If you take your spreadsheets and do a simulation whereby you force the death rates to be identical between vaccinated and unvaccinated and compute your "statistical method", you could test the validity of your method.
If valid, in that case the ratios should be 1.00 across the board. But when you do that simulation, you see the same type of pattern you demonstrate in your analysis of the real data -- with normalized ratios >1.00 and increasing over time -- in fact even higher magnitude than you get for the real data.
This shows your method is completely invalid. It preordains false conclusions that "vaccines increase death risk"
https://grok.com/share/bGVnYWN5_34a91df2-8397-4daa-896c-5c703b467c75
Grok had a non flattering description when I fed it your report